Introducing Megafilter
In my previous blog post I wrote about my idea for a google reader replacement suitable for my workflow. It’s written in NodeJS, and can load subscriptions from a google-reader takeoout.
The source is available on github.
Why not use an MVC framework?
Using the rather useful todoMVC I decided on backboneJS as the framework to use. However, the learning curve was too much to justify using it for the first release. I may switch to it later as a learning exercise.
For the first release (v0.1) I have decided to use jQuery instead, but with an MVC-ish approach. Specifically, I used a controller-based system.
Each (possibly generic) UI element has associated data (which could be considered the model) DOM elements and CSS (which is akin to the view) and methods to manipulate it, which is analogous to a controller. For example, the nav elements share a generic controller class.
Why not typescript?
Typescript is a superset of Javascript and adds much-needed features such as inheritance, static types, interfaces and quite a lot more. The only problem is, using it with nodeJS just isn’t worth the bother it creates. Maybe when the features make it to ECMAscript I will look at it again.
Designing the API
Following some research, I decided to choose between socket.io, restify and express-resource. Socket.io presents a websocket system, whereas the latter two present a RESTful JSON API.
I’ve never made a proper RESTful JSON API and socket.io websockets would limit the client platform scope of the entire project; so for me, the choice of a RESTful API was obvious.
Having used expressjs before, I looked at express-resource first. After removing the server-side MVC system that express presents, I found the system too restrictive; it enforces default actions. Also most of express is unneeded in this situation as this is a fully client-side rendered app.
I settled on restify as it was incredibly easy to use, and also allowed static file serving for the interface.
Differences to google reader
The biggest difference is the lack of infinite-scrolling. This is a deliberate move; I felt there were many problems with Google’s implementation:
- Keeping something unread was annoying on multiple visits, as scrolling past it would ‘read’ it
- Memory usage can be an issue, unless articles are garbage collected
- Loading images can cause the entire document to re-flow and the position lost. Images would have to be sized before loaded.
- Scrolling would ‘read’ the next article too soon causing the need to ‘mark as unread’ again
- It’s harder to focus on multiple articles at once
Google have fixed 2&3, but it would be a pain to do so in this case.
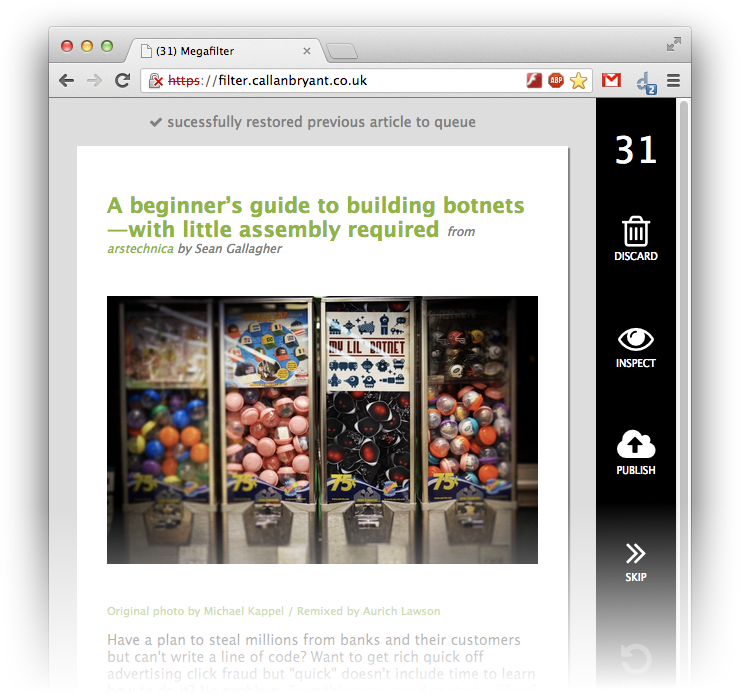
I have also focussed on publishing (starring) items. This is to suit my work-flow, which tends to be:
- Look at an article
- Read it later (skip) or now (inspect) if I find it interesting, or discard it
- Publish it to my website if I like it
Thanks for reading! If you have comments or like this article, please post or upvote it on Hacker news, Twitter, Hackaday, Lobste.rs, Reddit and/or LinkedIn.
Please email me with any corrections or feedback.